Hva er kunstig intelligens?
Kunstig intelligens er et vidt begrep som i dag brukes om mange former for algoritmer, maskinlæring, modeller og statistiske metoder.
Hvordan defineres kunstig intelligens?
Kunstig intelligens er et vidt begrep. Det knytter seg til flere fagfelt, slik som informatikk, psykologi og filosofi. Definisjonen vil kunne avhenge av fagfelt. I dagligtalen er begrepet "kunstig intelligens" nært knyttet til informatikk og brukes om mange former for algoritmer, maskinlæring, modeller og statistiske metoder.
Det har vært store gjennombrudd knyttet til maskinlæring de siste årene. Mange bruker kunstig intelligens som et begrep når det er maskinlæring det siktes til.
Definisjon i den nasjonale strategien for kunstig intelligens
I den nasjonale strategien for kunstig intelligens er kunstig intelligens definert som:
"Kunstig intelligente systemer utfører handlinger, fysisk eller digitalt, basert på tolkning og behandling av strukturerte eller ustrukturerte data, i den hensikt å oppnå et gitt mål. Enkelte KI-systemer kan også tilpasse seg gjennom å analysere og ta hensyn til hvordan tidligere handlinger har påvirket omgivelsene."
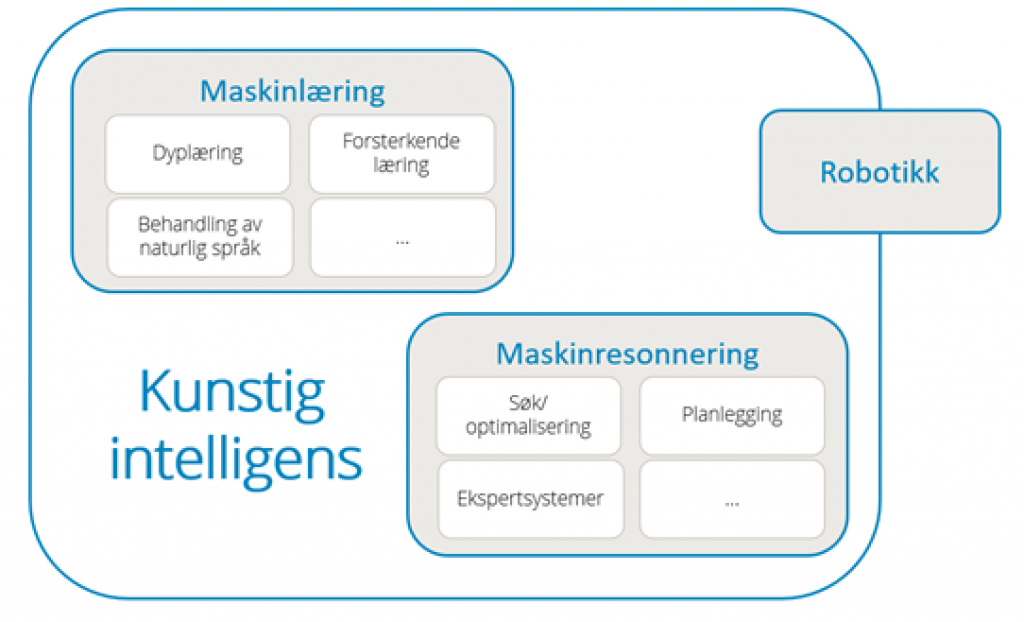
Som fagdisiplin inkluderer kunstig intelligens ulike tilnærminger og teknikker, slik som maskinlæring (inkludert eksempelvis dyplæring og forsterkende læring), maskinresonnering (inkludert planlegging, søk og optimering) og enkelte metoder innen robotikk (som kontroll, sensorer og integrasjon med andre teknologier i cyber-fysiske systemer).
Definisjonen i kunstig intelligens-forordningen
I det nyeste utkastet til den nye forordningen for kunstig intelligens (KI-forordningen) defineres kunstig intelligens i artikkel 3 (1).
Definisjonen i artikkel 3 (1):
«'(A)rtificial intelligence system' (AI system) means a machine-based system that is designed to operate with varying levels of autonomy and that can, for explicit or implicit objectives, generate outputs such as predictions, recommendations, or decisions that influence physical or virtual environments."